
BYOC Isn't "SaaS Anywhere": A Design Playbook
A playbook for delivering your SaaS and AI to customer-hosted environments, based on our experience building Tensor9.
TL;DR
BYOC succeeds with a holistic architectural plan, not bespoke deployments
Control-plane + data-plane isolation is the cornerstone; everything else supports it
Invest early in observability and version policy, or you'll drown in support
We’ve watched dozens of engineering teams learn these lessons the hard way. Here is the architecture that solves them.
Every SaaS company eventually faces the same question: "Can you run this in our environment?"
Before Tensor9 was the product it has become today, we worked with high-growth SaaS companies struggling to answer that exact question. We saw the same story play out in every sales conversation. A Fortune 500 prospect would love the platform but couldn't send data outside their network. A healthcare company needed on-prem deployment for HIPAA. A financial services firm required deployment in their own AWS account.
The initial response is almost always the same: teams fork their infrastructure code and create a "customer-hosted" variant. Six months later, they have three variants that share almost nothing, a support backlog they can't escape, and engineers who dread the words "enterprise deployment."
We call this "The Fork of Regret." We’ve seen teams where every feature had to ship three times. Every bug had to be fixed three times. It is unsustainable.
The mistake isn’t offering BYOC. The mistake is treating it like "SaaS Anywhere", as if you could take your hosted stack and simply run it somewhere else.
This post is what we wish someone had told us then. It's the playbook we built after learning the hard way.
Why BYOC, and Why Now
Why is this shift occurring now? It comes down to four non-negotiable demands from the market:
AI rewards bringing compute to data. Moving petabytes across environments to run inference isn't practical. The economics only work when you bring the model to the data.
AI agents need to live where they operate. Agents that interact with internal systems, such as databases, file stores, and APIs, work best when deployed inside the security perimeter. Tunneling tool access through external services creates an attack surface and latency that enterprises won't accept.
Data sovereignty is non-negotiable. Private AI and enterprise SaaS rely on governance that requires sensitive data to remain within a trusted boundary. Regulations like GDPR, HIPAA, and industry-specific requirements make this mandatory, not optional.
Security teams demand auditable software. Clear lines of responsibility regarding who can access what, when, and why are table stakes for enterprise procurement.
BYOC addresses all four by placing your runtime next to the data while centralizing policy, identity, health, and upgrade orchestration in your service environment.
The Architecture That Actually Works
We approached BYOC architecture from first principles, with a core constraint: minimize network access between vendor and customer environments. After iterating on this problem across different stacks and industries, the architecture we standardized on, and the one we recommend, strictly separates two planes:
Control Plane (Vendor-Managed): Your cloud hosts the central service for management, licensing, support, updates, and monitoring. This is where you maintain operational control without touching customer data.
Data Plane (Customer-Resident): Compute-heavy components like database engines, AI frameworks, and your core application logic run in the customer's environment under their control.
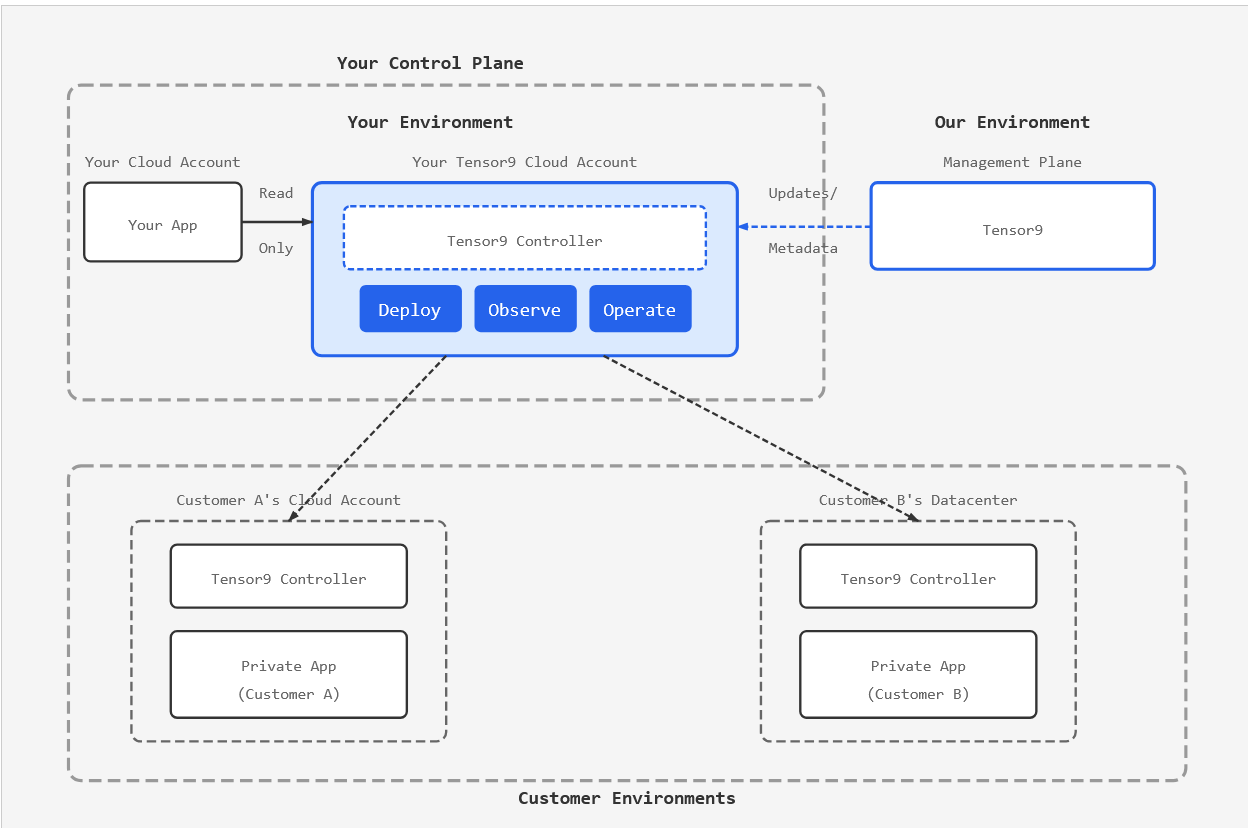
BYOC Architecture: Your control plane orchestrates deployments to customer environments
A narrow, audited connection carries metadata and optional audited telemetry between them. All communications are secure, and least-privilege permissions are enforced.
The key insight: metadata (deployment health, versions, error rates) is different from payload data (customer content). You can surface the former without touching the latter.
We didn’t invent this pattern at Tensor9. It's the same successful model used by Snowflake, Databricks, and MongoDB Atlas. The innovation isn't the pattern, it's making it work reliably across hundreds of different customer environments.
The Hard Parts (And What We Built)
BYOC is only viable if you design for the realities you don't control: heterogeneous environments, limited visibility, and shared security. Here's what we learned.
Heterogeneity Isn't an Edge Case
The cloud is not a singular place. It's a series of environments with meaningful differences that are guaranteed to surface at the worst times if you don't plan for them.
In the first 20 deployments we helped orchestrate, we encountered:
Managed Kubernetes (EKS, GKE, AKS) with different CNI configurations
Bare metal clusters with custom networking
Air-gapped environments with no internet access
VMs with varying ingress/egress rules
Custom certificate authorities and proxy requirements
While standardization is appealing, it often conflicts with customer security requirements. You can't tell a bank to reconfigure their network to match your assumptions.
What we built: Every deployment begins with capability assessment and conformance testing. We build a customer profile, then apply safe defaults or block operations with guided remediation. If a customer's environment lacks a required capability, we tell them exactly what's missing and how to fix it before deployment, not during.
Observability Where the System Lives
In a multitenant SaaS, a latency spike appears on your dashboards in minutes. In BYOC, your software lives inside someone else's perimeter, and you won't see much unless you design for it.
Many vendors initially choose to export almost nothing to avoid risk. Bad idea. When incidents happen, they can’t tell if the issue is the customer's network, a dependency, or their own components. Debugging takes days instead of hours.
We once watched a talented engineering team take 72 hours to resolve a standard incident. 60 of those hours were spent just trying to understand the customer's environment, not fixing the bug.
What we built: We ship collectors inside the customer environment and provide dashboards to build trust and transparency. We send versions, heartbeats, error rates, and resource utilization to our control plane so we can spot incidents and take action without accessing customer data.
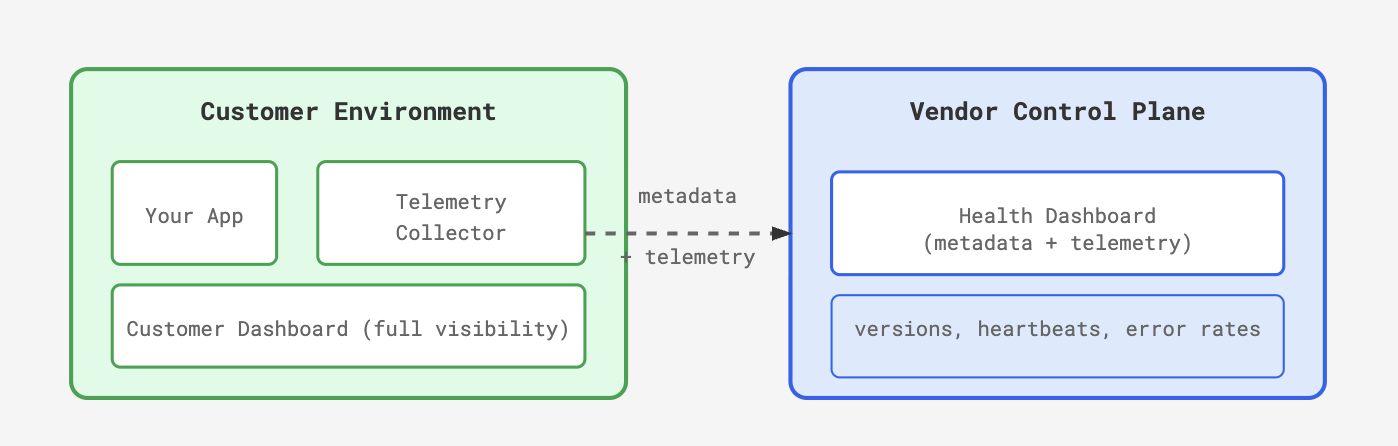
Telemetry architecture: Customers see everything, you only see metadata required to support them.
Support at Arm's Length
You can't mirror every combination of policy, topology, and data. Trying to reproduce every incident from scratch is monstrously time-consuming.
Without the right tooling, support tickets often take 3-4 back-and-forth exchanges just to understand the customer's environment before anyone can diagnose anything.
What we built: Diagnostics are a first-class interface to our support team. We provide a self-serve diagnostic package that gathers redacted logs, metrics, and configs with version control. When deeper help is needed, we use customer-authorized, temporary support access with enforced expiry and complete activity logging.
We also maintain a small set of certified deployment profiles representing our top cloud/Kubernetes combinations. They can't cover every edge case, but they dramatically shorten the path from "we've never seen this before" to "we know which subsystem is misbehaving."
Shared Security Without Ambiguity
BYOC blurs lines by design: your software needs privileges inside the customer account, and they control the perimeter and policies. If you don't clarify who secures what in advance, you'll drift toward over-privilege because it's the fastest path to "it works."
We learned this lesson sitting in a customer's security review that revealed a deployment requesting permissions it didn't actually need. The team had copied them from their SaaS stack without thinking. The offending permission: full S3 access when they only needed read access.
What we built: A clear delineation of security responsibilities, documented before deployment:
Who patches base images
Who remediates CVEs in container images
Who manages ingress/egress rules
Who rotates secrets
Who ensures the underlying hardware and OS are locked down
We implement least-privilege IAM by default and provide a security review template for customer teams. Data is protected with customer-managed keys, and your processes only see ciphertext.
Multi-Version Reality
In centralized SaaS, you have total control over the code version. In BYOC, your customers run many versions, including some that are 1-2 years behind. Enterprise customers are notorious for slowing down and gating change to minimize risk.
If you treat upgrades as major product releases, you're guaranteed to spend hours in your war room tending to a support backlog.
What we built: We make it easier and safer for customers to upgrade. Rollouts happen in groups using canary or blue-green patterns with explicit success criteria and automatic pause/rollback on early warning signs.
Install-time and upgrade-time compatibility checks block unsafe paths before they reach a live customer environment. We track adoption and drift the way a platform SRE would: measuring lag from GA to broad deployment, time-to-first-signal in incidents, and the percentage of installations not in the desired state.
Efficiency Is a Feature
SaaS software built for BYOC must be efficient because customers pay for their own compute, storage, and bandwidth. Inefficient design drives up costs, slows performance, and creates operational risk.
We watched a promising deal fall apart when a prospect ran a trial and came back with a compute bill that was 3x what they expected. They didn't become a customer.
What we built: Minimal footprint by default, especially in trials. Elastic scaling rather than max-capacity deployment. Backpressure and rate limiting for API management. The data plane degrades gracefully if the control plane is unreachable, providing local logging and diagnostics while customers keep working.
Day-0 to Day-2 Repeatability
Hand-built environments drift and generate inconsistent failures. Provisioning must be repeatable and reviewable.
Our original "customer-hosted" variant was a set of instructions and scripts. Each deployment was slightly different depending on who ran it and what decisions they made. Debugging was archaeology.
What we built: Infrastructure-as-code for everything. We use Terraform to define networks, clusters, storage, roles, and endpoints. We create the minimal, least-privileged resources needed by shipping modules for customers to run in their own accounts.
Declarative application delivery (Helm plus GitOps) ensures infrastructure stands up predictably and the runtime lands with strict schema validation and drift control. This accelerates onboarding and reduces the environmental variance that makes support difficult.
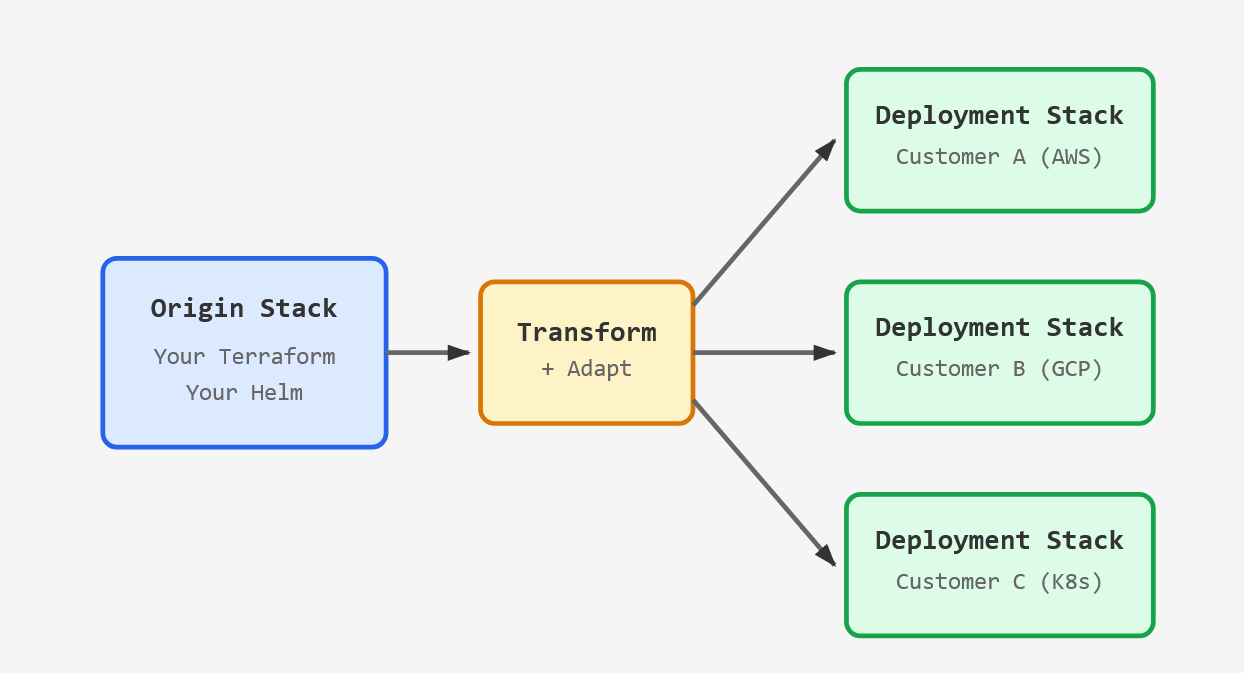
Infrastructure as code: Define once, transform for each customer’s environment.
Other Hard Parts
This playbook focuses on the foundational challenges, but there are other hard parts you'll need to think about that we haven't covered in depth here:
State drift reconciliation. When a customer's admin manually changes a security group, your next deployment needs to handle it gracefully. Detecting drift is straightforward; deciding what to do about it requires policy decisions that vary by customer.
IAM-to-RBAC translation. AWS IAM policies don't map cleanly to Kubernetes RBAC or GCP IAM. You'll need strategies for handling common patterns and clear processes for edge cases that require manual configuration.
Debugging across trust boundaries. When something fails in a customer's environment, your visibility is limited by design. Invest early in diagnostic tooling that gives you actionable signals without requiring direct access.
Air-gapped environments. No network connectivity to the control plane requires a fundamentally different operational model. Plan for this early if it's in your customer base, because retrofitting is painful.
If someone tells you they've solved BYOC completely, they either have a narrow use case or they're not being honest about the complexity.
Advice for SaaS and AI Companies
All that's great, but what direction should a SaaS or AI startup take?
Small teams have to pick their battles. BYOC delivery and support devour engineering cycles. First, determine if it's a technical differentiator. If selling into enterprise data shops or regulated industries basically requires BYOC, prioritize building it and build it right. If not, build a strong "traditional" SaaS first and put your resources into the core product, customer experience, and support.
Weigh revenue against DevOps effort. When a customer requires cloud-prem or on-prem, weigh the revenue against the engineering cost. Shifting developer focus from your core product can be risky, potentially derailing your business.
You don't need to reinvent the plumbing. This is why we built Tensor9. The platform handles portability, deployment, observability, and simplified operations with minimal changes to your existing codebase. But even if you don't use us, consider whether building this infrastructure is the best use of your engineering team's time.
The Payoff
Treat the hard parts as design inputs, not afterthoughts, and you earn speed and trust.
The operating model is holistic: a single control plane sets identity, policy, and desired state while multiple hardened data planes run close to customer data under their control. Disciplined upgrades plus observability keep operations predictable.
When you invest early in conformance testing (to block bad environments), metadata telemetry (to surface deployment health without touching payloads), and phased rollouts (to mitigate risk and minimize disruption), you turn BYOC from a tax into a competitive moat.
We still have more to build. But the playbook above is what's worked for us in helping many vendors deliver their products into customer environments, and we hope it saves you some of the pain we went through.
What to Look For
Whether you're building BYOC infrastructure yourself or evaluating platforms, here are the capabilities that matter. No solution covers all of these perfectly, so the real question is which gaps you can live with.
Control & Deployment
Every install ties back to a central controller
Clear release stages and version tracking
Drift detection (remediation is harder)
Environment Safeguards
Validate customer infrastructure before deployment
Least-privilege access by default
Resource sizing appropriate to customer scale
Packaging & Delivery
Standardized deployment templates
Repeatable upgrade paths
Observability & Support
Telemetry that flows to you without exposing customer data
Customer-visible dashboards for transparency
Audited support access with customer approval
Security & Access
Clear responsibility boundaries documented
Customer secrets stay in customer environment
Audit trails on both sides
Upgrades & Rollouts
Support for multiple versions in production
Safe rollout patterns with rollback capability
Compliance
Data residency guarantees
Path to SOC2 or equivalent certification
Clear runbooks for common operations
Focus on Your Product, Not Plumbing
Ultimately, the architecture matters more than who builds it. If you have the resources to construct the control-plane/data-plane model yourself, the playbook above is yours to use. Just remember that maintenance is forever.
We founded Tensor9 because we believe your engineers should be building your core product, not reinventing deployment plumbing. If you want to skip the 18 months of infrastructure work and get straight to shipping, we’d love to chat.